Parquet Column Cannot Be Converted In File
Parquet Column Cannot Be Converted In File - I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: If you have decimal type columns in your source data, you should disable the vectorized parquet reader. The solution is to disable the. Int32.” i tried to convert the. Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. Learn how to fix the error when reading decimal data in parquet format and writing to a delta table. When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. You can try to check the data format of the id column.
Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. The solution is to disable the. I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: Int32.” i tried to convert the. You can try to check the data format of the id column. When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. Learn how to fix the error when reading decimal data in parquet format and writing to a delta table. If you have decimal type columns in your source data, you should disable the vectorized parquet reader.
The solution is to disable the. I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: Learn how to fix the error when reading decimal data in parquet format and writing to a delta table. Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. Int32.” i tried to convert the. You can try to check the data format of the id column. If you have decimal type columns in your source data, you should disable the vectorized parquet reader.
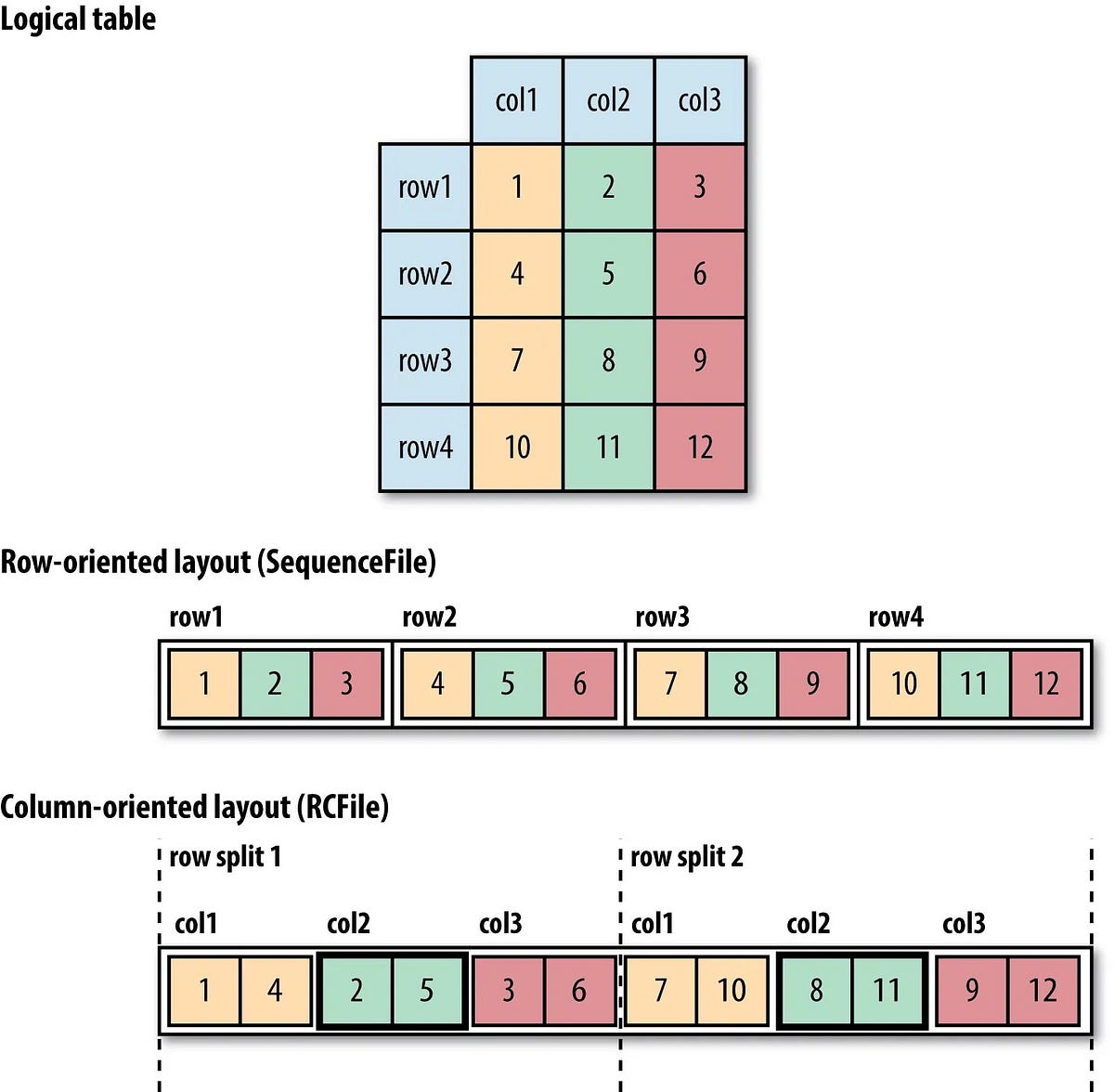
Why is Parquet format so popular? by Mori Medium
You can try to check the data format of the id column. Learn how to fix the error when reading decimal data in parquet format and writing to a delta table. Int32.” i tried to convert the. Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. The solution is to disable the.

Parquet はファイルでカラムの型を持っているため、Glue カタログだけ変更しても型を変えることはできない ablog
The solution is to disable the. When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. You can try to check the data format of the id column. Learn how to fix the error when reading decimal data in parquet format and writing to a delta table. I.
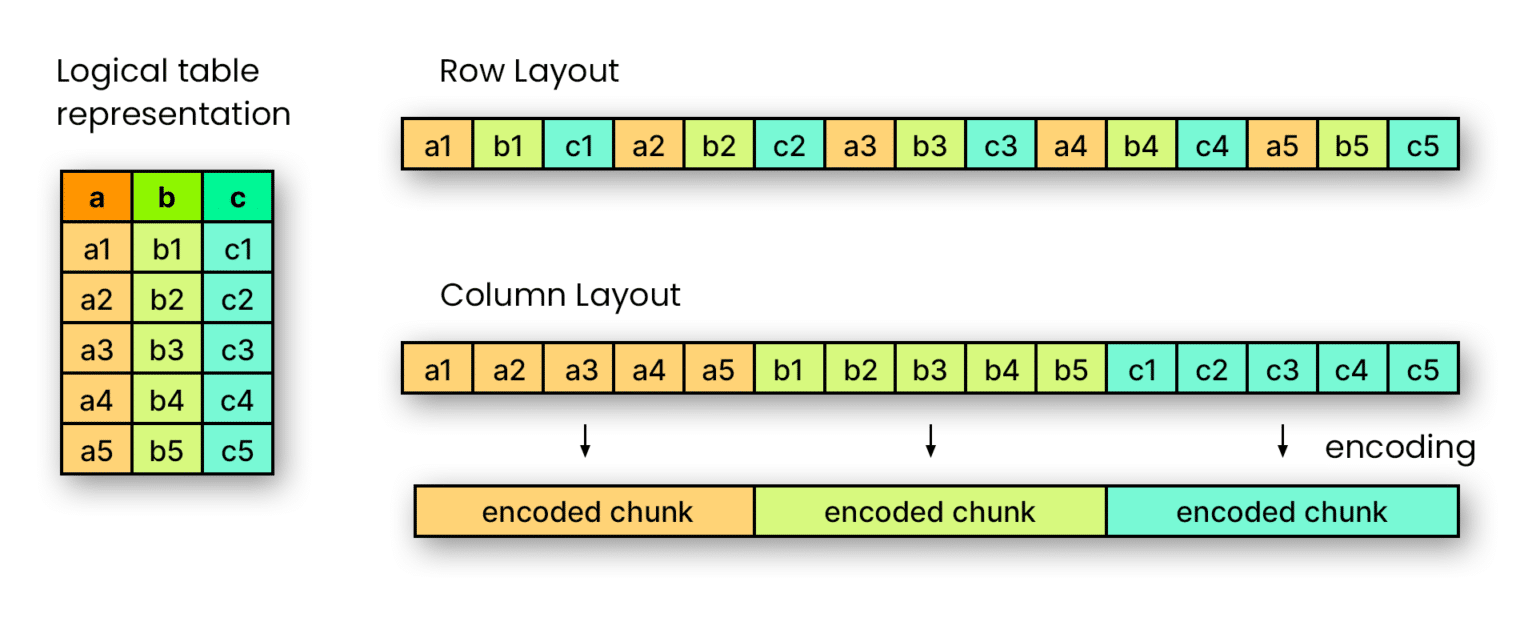
Understanding Apache Parquet Efficient Columnar Data Format
Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. The solution is to disable the. Int32.” i tried to convert the. If you have decimal type columns in your source data, you should disable the vectorized parquet reader. When trying to update or display the dataframe, one of the parquet files is.

Spatial Parquet A Column File Format for Geospatial Data Lakes
When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: The solution is to disable the. Spark will use native data types in parquet(whatever original data type was there in.parquet files) during.

Demystifying the use of the Parquet file format for time series SenX
I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. Int32.” i tried to convert.

Parquet Software Review (Features, Pros, and Cons)
If you have decimal type columns in your source data, you should disable the vectorized parquet reader. When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. Learn how to fix the error when reading decimal data in parquet format and writing to a delta table. Int32.” i.
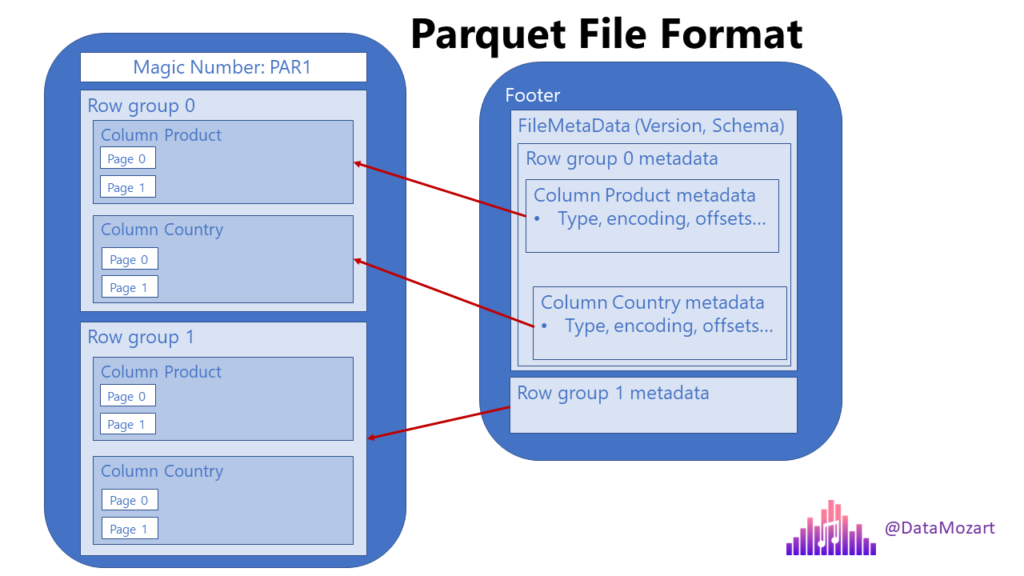
Parquet file format everything you need to know! Data Mozart
When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: If you have decimal type columns in your source data, you should disable the vectorized parquet reader. You can try to check.

Parquet file format everything you need to know! Data Mozart
You can try to check the data format of the id column. Learn how to fix the error when reading decimal data in parquet format and writing to a delta table. Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. The solution is to disable the. When trying to update or display.
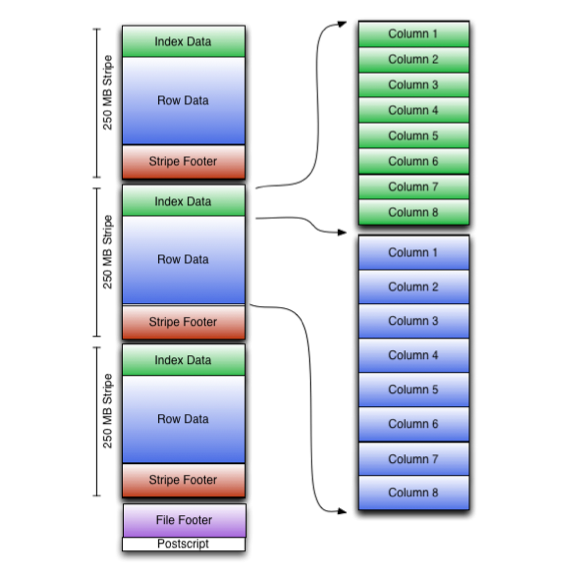
Big data file formats AVRO Parquet Optimized Row Columnar (ORC
The solution is to disable the. Learn how to fix the error when reading decimal data in parquet format and writing to a delta table. If you have decimal type columns in your source data, you should disable the vectorized parquet reader. I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: When trying.
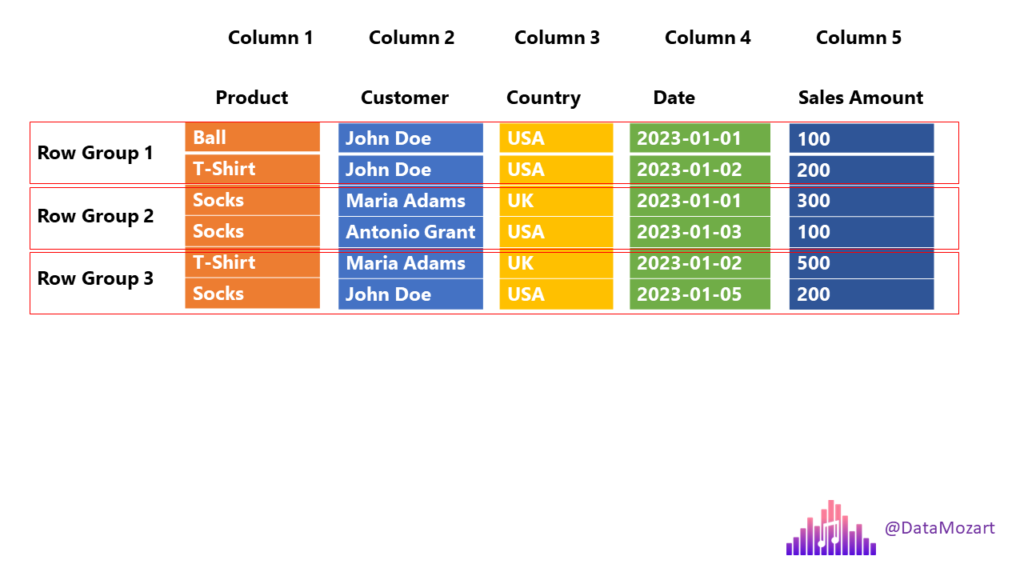
Parquet file format everything you need to know! Data Mozart
Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. When trying to update or display the dataframe, one of the parquet files is having some issue, parquet column cannot be converted. I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: You can try to check.
You Can Try To Check The Data Format Of The Id Column.
I encountered the following error, “parquet column cannot be converted in file, pyspark expected string found: Int32.” i tried to convert the. If you have decimal type columns in your source data, you should disable the vectorized parquet reader. The solution is to disable the.
When Trying To Update Or Display The Dataframe, One Of The Parquet Files Is Having Some Issue, Parquet Column Cannot Be Converted.
Spark will use native data types in parquet(whatever original data type was there in.parquet files) during runtime. Learn how to fix the error when reading decimal data in parquet format and writing to a delta table.